Contents
Notes From Figma II: Engineering Learnings
This is part II of my notes on Figma, which will focus on my technical and non-technical learnings from Figma - problems in our domain, how I grew as an engineer, and how Figma's culture shaped our work. The first part, which talks about what brought me to Figma and my take on why Figma succeeded is here.
What technical things did I learn at Figma?
Constraints of the web
The web's unparalleled distribution is a double-edged sword. It's a single platform with vast reach: not only is it write once, run anywhere for developers, but it's zero install, instant play for end users. But its universality means it moves slowly. In many ways it's a highly constrained, backwards platform only now catching up to decade-old developments in hardware and low-level technologies. For example:
- Multithreading: This only became practical in the last few years. For a long time, web workers were a poor implementation, especially since SharedArrayBuffers were disabled across browsers from 2018-2020 due to security concerns, meaning message-passing was the only possible communication mechanism between workers.
- 64-bit memory: As of July 2024 WebAssembly still only supports 32-bit addressing, meaning 4GB is the most memory you'll ever be able to work with, short of tricks like paging out to JavaScript. In fact, even 4GB wasn't possible in Chrome until 2020 due to limitations in V8. This meant we would actually run into out-of-memory issues on desktop, which came as a surprise to users running top-of-the-line machines that could handle other apps just fine.
- SIMD: This is still just a WebAssembly proposal, albeit one with decent support in the major browsers (just not older versions of iOS Safari!).
-
Screen recording and color picking:
getDisplayMediaonly reached widespread support in mid 2019. The EyeDropper API was launched in late 2021 and is still only available in Chromium and Firefox browsers.- This is relevant for the "eye dropper" functionality in design tools where you can click anywhere on the canvas to get the color value at that point. Different tools had to hack around this limitation in different ways. For Figma, since we built our own rendering stack from scratch, we were able to implement our own color picker without the use of these APIs.
- But for our competitors using the DOM for rendering, this was a major limitation. For instance, for a long time, to use the eye dropper in Framer, you had to download the desktop version, but they eventually added the functionality via screen recording in Framer Web.
-
Memory management: Memory management on mobile especially is a hot topic in the WebAssembly Community Group.
- WASM memory is grow-only (although there is a memory control proposal which would allow the application to release memory back to the operating system), so bursts in activity grow application footprint permanently, making it much more likely to be killed over time.
- In practice, growing memory at runtime is notoriously unreliable on many mobile devices, with calls often leading to crashes, so the best practice is to allocate the maximum amount of memory that developers think their app will use ahead-of-time.
- For Figma and many other apps with user-generated content or highly dynamic workloads, it's impossible to know this beforehand. So we'd simply over-allocate initially. This led to UX issues like the app being killed when backgrounded on mobile when the workload wasn't actually all that high.
-
Debugging and profiling:
- Ok, the Chrome profiler is amazing, and Chrome WASM Debugging via DWARF is quite good now!
- What wasn't so good was debugging on mobile Safari. Trying to debug memory and performance issues on Safari was very tricky. Recording profiles was finicky as the the timeline tool would sometimes only begin recording one type of timeline, or start at weird times, or crash and reload, while other times the remote debugger would simply not show connected iPhones at all.
-
This in combination with the memory management issues above and the trigger-happy OOM watchdog made the platform a nightmare for us to develop for. Around the time I left,
the mobile team hired some folks who had worked on Safari at Apple who had many tips (for instance, using the
footprintapp with the iOS simulator which gave more reliable measurements than attempting to use Safari tools on a physical device, and was theoretically the same software), so I have some hope the situation is improved.
-
GPU APIs:
- As of writing, out of the major browsers, WebGPU is still only enabled by default on the Chromium-based ones (and only since last year). This is despite Metal (2014) being a decade old now (and CUDA from 2007 being even older). So to build for the wider web, you have to use WebGL 2.0, which is based on OpenGL ES 3.0 from 2012, which is a pretty pale attempt at a modernization of the ancient OpenGL ES 2.0 standard from 2007, all of which lack proper GPGPU support!
- At Figma, we were lucky enough that the things we wanted to do on the GPU weren't all that complicated. This is not to say that the rendering tech we had wasn't advanced or that 2D vector rendering doesn't have anything interesting going on, it's just that fast-enough algorithms could be implemented fairly straightforwardly on older architectures with only vertex and fragment shaders, and beyond that, most use cases of our product would benefit more from optimizing other, more CPU-bound parts of the system.
What's interesting is that most software - even native software - doesn't take advantage of the hardware features listed above, and Figma was able to exploit this. It came out in 2015 using a web standard based on 8-year old technology (WebGL). Rendering 2D vectors on the GPU wasn't a new idea either (Loop-Blinn was a decade old by then) yet Sketch - its MacOS native competitor - barely even used the GPU!
Design tools have multiplicative complexity
My colleague Rudi pointed this out a while back. Basically, when you're designing a set of primitives that all go in the same space (the canvas) which people are going to combine with each other to make things, everything needs to work with everything else.
To illustrate this, let's imagine a simple version of Figma where we let people put rectangles and text on the canvas, change their color, and directly manipulate (select, move, and resize) them with the mouse. In the image below,
our app is shown with the layers panel on the left, the toolbar in the middle, and properties of the currently selected object (Text 1) on the right:
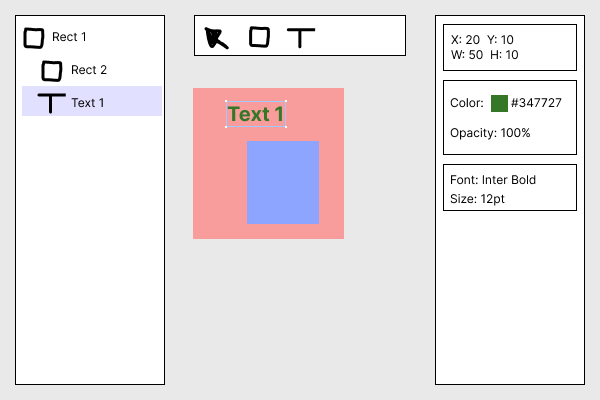
Already we have some questions:
- What properties should we display in the right panel when you select
Text 1andRect 1together? - When you resize your selection, should all elements scale uniformly, or should they resize like how you might resize a UI element, e.g. with the text staying the same size, just moving around?
- What happens when you resize a text object, or change its contents so that it gets too big for its current size? Should the “box” representing your selection stay the same with the characters just flowing outside of it, or should the box grow to fit, or should the characters within try to reflow to stay inside the box somehow?
We only have two types of objects and a handful of operations and info panels, yet we already need to consider how resizing can behave differently given different object types, or how the right-hand panel might behave differently given heterogeneous selections. Some of these questions are more product-related (how resizing a selection of multiple objects should behave), while others are more engineering-related (how we might efficiently handle reflowing large amounts of text). And this is all before we throw in multiplayer, auto-layout, and components!
What non-technical things did I learn at Figma?
Crucial re-architectures
I joined Figma at a unique time in the codebase's health where - a few years after the initial launch and the team building as fast as possible - the business was beginning to really take off but the accumulated tech debt was on the verge of catching up to us.
The codebase had a foundation of tight, well-documented systems which came from the earliest years of the company (before Figma was released, when the team was small and had time to internally iterate), but beyond that, accidental complexity abounded. When newcomers asked “why does X system work this way”, a common refrain was: it's just like that, because we were building under pressure, that's what we came up with, and we never had time to rethink it!
The underlying reason was, of course, competitive pressure. Our tech had given us a head start at launch, but our competitors had taken notice, and by 2019 were furiously chasing after us in collaboration features and threatening to pull ahead in editor features like auto-layout and prototyping animations.
So the prevailing sense in the editor teams was urgency, and while we did strive to perfect the design of our features before releasing them, the engineering behind them often took on considerable debt. This led to some weird code: for example, to ship auto-layout, we built two separate layout engines managing
different parts of the document with some overlap, which was a constant source of subtle bugs and performance issues for years after. It also meant that learning all the weird quirks of the engine became perhaps more valuable than being a fast problem solver
One time where this came to a head was in the architecture behind our components feature: our original architecture had a ton of accidental complexity and made important operations very difficult to reason about. This was blocking several key features, so the team decided to bite the bullet and completely redesign it, which required two huge combined refactoring-and-migration projects, and the creation of a system for file-wide migrations in our backend, which we had somehow gone for years without having. It was a heroic effort, and succeeded I think because of engineers like Joey Liaw, who led the project and had also been part of the healthcare.gov rescue team.
That said, some re-architectures failed, even the ones with the same hero engineers working on them. For instance, a large project to rework the engine's core datastructures in 2018 failed. But these failures were not critical, partly because we always undertook them in a way that didn't disrupt ongoing product development.
So what happened? Did we just get lucky? If I had to pick a dividing line between the failures and successes, it's that the successes always had a product goal in mind ahead-of-time.
For instance, both the components re-architecture and another mobile viewer re-architecture I worked on aimed at unlocking a product roadmap, with the latter also improving performance.
The failures, on the other hand, aimed to make code easier to reason about - meaning “reduce bugs”
Here's what I'd claim: these product-driven re-architectures were crucial to our success, and while they sometimes required heroic efforts to succeed, this wasn't a symptom of dysfunction; instead, in the early days it was optimal for us to go through these cycles of building fast and taking on debt, then attempt refactors as needed, because we were racing to stay ahead of our competitors in a fast-moving space.
The Mythical Stakeholder Alignment
I spent my first couple years as a product engineer. I was not a very good product engineer.
I was ignorant of the urgent dynamics in the editor product at the time, and had a habit of misunderstanding or interpreting ambiguous requirements in ways that increased scope (because of the same instincts that would lead me to work on the platform - everything had to be clean and performant!). But because I was good at fixing bugs fast and soaking up trivia about the codebase, I was trusted by the team to take on larger projects and maybe mistakenly seen as a high performer.
In my first year, this led to me working solo on a refactor which had to be scrapped after a few months because I thought it needed to support more than it actually needed to. At the time it felt catastrophic, but looking back it wasn't all that bad - the failure didn't significantly impact the rest of the company but was a big learning moment for me.
On the other hand, I suspect my stint as a poor product engineer made me a better platform engineer: I knew what it was like to interface with product and design folks, what they valued and how they communicated it, and how to use this to flush out the biggest risks and distill the highest priority requirements.
For instance, I led a later project that overhauled our whiteboarding renderer to improve FPS, and our initial idea (throttling canvas rendering to improve overall responsiveness) seemed concerning to basically everyone working on on-canvas features. However, we were able to quickly establish that the optimization could activate selectively and usefully, that the critical times where it had to be disabled were few and far between, and that risks like system de-synchronization either weren't issues or could be easily mitigated.
How did we do it? We talked to people! We held meetings and wrote docs, but also, since folks at Figma are big on seeing and trying things out, we built a demo, recorded videos demonstrating what magical terms like system de-synchronization actually looked like, and later when we landed it in staging, we built in a subtle UI indicator that would appear to let folks know when our optimization was active.
In other words, I had learned how do this mythical thing that people call “building alignment”: in a large company, where both the software and its use cases are too complex to fit in any one person's head, I had enough of an understanding of the system being optimized to know when an idea (that someone else came up with!) was locally possible, and of the product and org (the connected surfaces and the folks who understood them) to know or find out if it was globally possible, too.
Figma's engineering culture
Importance of side projects. At Figma, we had a culture that encouraged side projects - toys or programs that folks would create which nobody asked them to, which did not necessarily have an impact on the bottom line, but which could be used to explore new ideas or technologies. Many features and innovations came out of side projects. Just off the top of my head:
- Our internal offline document inspector, figmascope
- A performance profiling tool (also widely used outside of Figma), speedscope
- The widgets feature where you could make React components that went on the Figma canvas
- Various April Fools features like custom cursors
- The video feature of Figma prototypes
Two things made it work for us:
-
The culture was fostered by leadership from the earliest days of the company. Indeed, it's part of Figma's mythos - in the San Francisco office, there's a coffee table sculpture of the "WebGL Water" demo that Evan Wallace built back in 2010. And it wasn't just Evan - leaders would regularly take time out to play around with new ideas. For example:
- My first manager Ryan spent a lot of spare time getting deep into rendering of all kinds, from WebGL rendering techniques that we didn't already use to exploring DOM-based renderers for Figma.
- Our product head Sho maintained a "toy Figma" built in React that he would use to quickly try out new ideas.
-
We had time specifically set aside for side projects. Companies have different strategies for this: for instance, Google is famous for letting employees spend 20% of their time on side projects. Our policies were a bit more ad-hoc, but we had both explicit time in the form of "maker weeks" (which were twice a year and actually a whole week long each) and implicit time in the form of extra-long holidays
Obviously, you were not expected to do any work over the holidays, and I think now that we're a large company most people should and do use them for recharging. But work was not discouraged either, and when you're heavily invested in a small startup and have nothing else going on... .

The sculpture of the "WebGL Water" demo seen in the Figma office before the pandemic.
Why were side projects important to us?
- It gave us time to explore new ideas or technologies without external pressure or requirement that they help our bottom line.
- The reserved time without interruptions let us go deep into our ideas and get spikier, which let us beat the averages.
- While less specific to side projects, prototyping things out to give people something concrete to play with helped us perfect design primitives before releasing them to the wider world. For instance, auto-layout actually existed for years behind a flag in the product (and was even reverse-engineered by Twitter at some point!). This is not to say that we didn't value iterating on public feedback, but that our product was complex enough that some features needed to be really thought through before release because of the multiplicative complexity of our product.
It's interesting contrasting our culture with the one that many of my ex-Dropboxer colleagues came from, where (I was told that) side projects were frowned upon because it meant you weren't spending enough time working on your main project.
Another interesting question is when side project culture doesn't add value anymore. As with so many things in company cultures, I think side projects don't really scale with company size. In the early days of a startup, folks are much more incentivized to spend their free time on exploring ideas that are genuinely relevant to the business, since they have a greater stake in its success. But larger companies are often more averse to revolutionary new ideas due to having well-established businesses, and I'd guess that the ideas folks explore if given the opportunity would be more driven by what is better for their own careers, and only relevant to the company insofar as they fulfill "hack time" requirements and come from opportunities in the company's systems.
Geeks attracted to a weird tech stack. We had (and still have) a stellar team with lots of browser and graphics hackers who had cut their teeth in the 90s and 00s. Partly we made intentional hiring decisions early on, but I think we were attractive because of our app's unique tech stack which made it like a browser within a browser or an MMO. For example, among my colleagues were a teammate who interned at Netscape and worked at Mozilla through the birth of the open web platform, and multiple other teammates who'd built videogames during the "masters of doom" early 3D era.
PRs as documentation. PRs in my corner of Figma were specifically written with code archaeology in mind and providing context to changes line-by-line via git blame. For a bugfix, a PR might include in its description:
- What the bug was, who was running into it, and how important it was.
- Steps needed to manually test the fix and any automated tests that were added (or reasons they weren't added).
- Links to documentation, dashboards, or any other external resources that were updated.
Not every team did this, but my team did, and it was very convenient because months or years later, I could reconstruct the whole history of a module, including the reasoning for all the little hairs and bugfixes that made little sense on first glance. Most of the time it was also possible to reproduce the bug with the steps contained, and even decide that whatever fix was there could be deleted if needed (for example, as part of a refactor).
Another thing we did that I haven't seen elsewhere is structure larger PRs so that they were readable commit-by-commit. No matter what order we had done our original changes in,
we would commit them in a logical sequence that made it clear what the PR was doing using a tool like git add --interactive. So for example if we were creating a new version
of a module that had a slightly different API and worked differently under-the-hood, our commits might look like so:
1111111: Copy-paste old library code into new files
2222222: Make changes to code and function signatures in new files
3333333: Add feature flag and update call-sites
This made changes extremely easy to review and doubled as a way for team members to learn how senior engineers thought.
3 things. We had a beloved tradition
The prompt was intentionally vague - it didn't have to be the 3 biggest or deepest things, it could be any 3 things. Some people reached down deep and revealed formative experiences of heartfelt pieces of themselves, while others talked about recent hobbies they were spending lots of time on or favorite books. I attended a bunch of these and felt that I really got to see beyond the professional veil to a more personal side of my coworkers, and I regret a bit not having participated.
A common question for company cultures is whether the company is more like a "team" or a "family", and it's also a matter of opinion which one is better. During my time there, Figma was at least on the surface much more like a family. Whereas companies like Netflix emphasize extraordinary candor, professionalism, and performance, Figma's culture emphasized empathy, mutual support, and growth, and 3 things more than anything else fostered empathy.
Did it work for us? I think it did, and miraculously it did so without sacrificing performance: the folks I worked with are still some of the most brilliant and productive I've met, while being some of the kindest
(Jamie, who is one of these people, calls them "humble wizards"). Yet it wasn't without tradeoffs: there were certainly times when I felt that we had over-emphasized support over candor
in communication, which made it hard to give or receive valuable feedback. But if I had to point at one reason why this culture worked so well for us, I think it was because the design tool space requires creativity,
and you need an empathetic, supportive environment to foster that
Acknowledgements
Thanks to Rudi Chen, Ryan Kaplan, and Jamie Wong for valuable feedback, quotes, and suggestions on multiple revisions of this post.